Table of Contents
- Chapter 1: Basics
- Chapter 2: Data Processing
- Chapter 3: Neural Networks
- Chapter 4: Convolutional Neural Networks
- Chapter 5: Recurrent Neural Networks
- Chapter 6: Generative Models
- Chapter 7: Attention Mechanisms
Chapter 1: Basics
The following 5 questions are just to warm you up in programming with Python.
Q.1: FizzBuzz
Write a program that prints the numbers from 1 to 100. But for multiples of three print “Fizz” instead of the number and for the multiples of five print “Buzz”. For numbers which are multiples of both three and five print “FizzBuzz”.
Q.2: Quick Sort
Implement a quick sort (divide-and-conquer) algorithm. You can read about it here.
Sample Input: [9, 8, 7, 5, 6, 3, 1, 2, 4]
Sample Output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Q.3: Missing Element
You are given two arrays. One is a shuffled version of another one, but missing one element. Write a program to find a missing element.
Sample Input: [2, 3, 4, 5, 6, 7, 5, 8], [6, 8, 7, 4, 5, 2, 3]
Sample Output: 5
Q.4: Pair Sum
You are given an array. Write a program to output all possible pairs that sum to a specific value k.
Sample Input: [1, 3, 2, 2], k = 4
Sample Output: (1, 3) (2, 2)
Q.5: Multiplication Table
Write a program that outputs a multiplication table like the following picture.

The following 5 questions are for NumPy. If you have used MATLAB, you will be just fine. The question are extracted from numpy-100 and you can practise more if you have time.
Q.6
Create a checkerboard 8x8 matrix using the tile function.
Q.7
Normalize a 5x5 random matrix.
Q.8
Multiply a 5x3 matrix by a 3x2 matrix (real matrix product)
Q.9
Given a 1D array, negate all elements which are between 3 and 8, in place.
Q.10
Consider two random array A and B, check if they are equal.
Chapter 2: Data Processing
In this chapter, we will do the first 10 knocks of image processing. If you don’t understand, please read the original image processing knocks which are originally in Japanese.
Q.1: Channel Swapping
Change the channel order from RGB -> BGR.
| Input | Output |
|---|---|
 |
 |
Q.2: Grayscale
Convert a color image to a grayscale one. The linear formula is
Y = 0.2126 R + 0.7152 G + 0.0722 B
| Input | Output |
|---|---|
|
 |
Q.3: Binarization
Binarize an image given the threshold is 128.
| Input | Output |
|---|---|
|
 |
Q.4: Binarization of Otsu
This is an automatic thresholding algorithm by minimizing intra-class intensity variance or maximizing inter-class variance.
| Input | Output |
|---|---|
|
 |
Q.5: HSV Conversion
RGB -> HSV and HSV -> RGV
In this case, invert the hue H (add 180) and display it as RGB and display the image.
| Input | Output |
|---|---|
|
 |
Q.6: Discretization of Color
Quantize the image as follows.
val = { 32 (0 <= val < 63)
96 (63 <= val < 127)
160 (127 <= val < 191)
224 (191 <= val < 256)
| Input | Output |
|---|---|
|
 |
Q.7: Average Pooling
Perform an average pooling of 128x128 image by 8x8 kernel.
| Input | Output |
|---|---|
|
 |
Q.8: Max Pooling
Perform a max pooling of 128x128 image by 8x8 kernel.
| Input | Output |
|---|---|
|
 |
Q.9: Gaussian Filter
Implement the Gaussian filter (3 × 3, standard deviation 1.3) and remove the noise of a noisy image.
| Input | Output |
|---|---|
 |
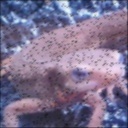 |
Q.10: Median Filter
Implement the median filter (3x3) and remove the noise of a noisy image.
| Input | Output |
|---|---|
|
 |
Chapter 3: Neural Networks
Q.1: Linear Regression
- Generate a synthetic dataset containing 1000 examples with addictive noise. Each sample consists of 2 features drawn from the standard normal distribution. The true parameter generating the dataset is \(w = [2, -3.4], b = 4.2\). Sample noise from normal distribution with mean 0 and standard deviation 0.01. Synthetic labels will be \(y = Xw^T + b + \epsilon\). Plot the features, we can clearly see the linear correlation between features and labels.
- Build a model \(\hat{y} = Xw^T + b\). The model will learn \(w\) and \(b\).
- Define a squared loss function.
- Initialize the model paremeters with random values drawn by normal distribution with mean 0 and standard deviation 0.01 and set the bias to 0.
- Use minibatch stochastic gradient descent to train the model.
- Print the errors between true parameters and learnt parameters.
Q.2: Softmax Regression
- We will use Fashion-MNIST dataset with a batch size of 256 and build a single layer neural network.
- Initialize the model parameters with Gaussian noise (normal distribution with mean 0 and standard deviation 0.01) and set the bias to 0.
- Define the softmax operation.
- Define the model. The only difference from the previous question is to apply the softmax operation to the output because now we are dealing with a classification problem.
- Define a cross-entropy loss.
- Train the model with minibatch stochastic gradient descent and plot the learning curve.
- Calculate the accuracy of the model.
Q.3: Multilayer Perceptrons
- We will build a neural network with a hidden layer (256 hidden units) and non-linear activation functions for Fashion-MNIST dataset.
- Initialize the model parameters with random values drawn from normal distribution.
- Define a model with ReLU activation function.
- We will use the same cross-entrop loss.
- Train the model with minibatch stochastic gradient descent and plot the learning curve.
- Calculate the accuracy of the model.
Q.4: Regularization
We do not want the model to memorize the training data. We will use generalization techniques to improve generalization of the model. Implement the following reqularization techniques by using a synthetic dataset or any dataset you like. Compare training with regularization and without regularization.
- Dropout
- Early Stopping
- Weight decay (L-2 regularization)
Chapter 4: Convolutional Neural Networks
Q.1: 2D Convolution
- Implement a 2D convolution layer. There are 2 parementers, the kernel and scalar bias. You can initialize the kernel with random values, bias can be zero.
Q.2: Edge detection
- Apply the convolution layer you implemented for edge detection in images by using edge detection kernels.
Q.3: Padding
- Either implement your 2D convolution to be able to do padding or use Pytorch Conv2D and experiment the convolution with padding.
Q.4: Stride
- Either implement your 2D convolution with stride or use Pytorch Conv2D and experiment the convolution with stride.
Q.5: Pooling
- Implement a 2D pooling layer that can handle both max and average pooling.
Q.6: LeNet
- Implement a LeNet in PyTorch.
- Train LeNet for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.7: AlexNet

- Implement AlexNet in PyTorch.
- Train AlexNet for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.8: VGG
VGG implements the idea of using blocks. Reference
- Implement a VGG-11 in PyTorch. You can reduce the number of channels in VGG since we are dealing with a small dataset.
- Train VGG for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.9: NiN Blocks
- Implement a NiN model in PyTorch. Reference
- Train NiN for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.10: GoogleNet (Inception)
- Implement Inception blocks(GoogleNet) in PyTorch.
- Train GoogleNet for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.11: Batch Normalization
- Implement Batch Normalization
- Apply Batch Normalization in LeNet.
- Train LeNet for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.12: ResNet
- Implement a ResNet-18 in PyTorch.
- Train ResNet for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Q.13: DenseNet
- Implement a DenseNet in PyTorch.
- Train DenseNet for Fashion-MNIST dataset.
- Plot the learning curve.
- Calculate the accuracy of the model.
Chapter 5: Recurrent Neural Networks
Q.1 Text Preprocessing
- Download The Time Machine
- Read the lines from the downloaded text.
- Write a function to tokenize each line (both word and character level).
- Create a vocabulary (dictionary) to map each string token into numerical index. (i.e., Count the unique tokens from the corpus and assign a numerical index according to its frequency)
- You can preprocess the time machine dataset as you like if you don’t want to follow above steps.
Q.2 Reading Sequence Data
- Consider both random sampling and sequential partitioning.
- Prepare data loader for the time machine dataset.
Q.3 Character-level Language Model by RNN
- Read the dataset.
- Define an RNN model in PyTorch.
- Train and Predict.
- You can also implement an RNN from scratch.
- You might want to plot perplexity vs epochs.
Q.4 Gated Recurrent Units (GRU)
- Explain GRU (what problem it is trying to address)
- Use the same time machine dataset.
- Implement a GRU.
- Compare the results with Q.3
- You might want to plot perplexity vs epochs.
Q.5 Long Short-Term Memory (LSTM)
- Explain LSTM.
- Use the same time machine dataset.
- Implement a LSTM.
- Compare the results with Q.3 and Q.4.
- You might want to plot perplexity vs epochs.
Chapter 6: Generative Models
Q.1 Autoencoders
- Explain what an autoencoder is.
- Impelement an autoencoder.
- Train the autoencoder by using MNIST dataset.
- Visualize the results.
Q.2 Variational Autoencoders (VAE)
- Note that VAE and AE are different.
- Explain the difference.
- Implement a VAE.
- Train the VAE by using MNIST dataset.
- Visualize the results.
Q.3 Generative Adversarial Networks (GAN)
- Explain GAN.
- Implement a basic GAN without any convolution by using MNIST.
- Visualize the results.
Q.4 Deep Convolutional GAN (DCGAN)
Main features of DCGAN are:
- Use convolution without using any pooling layer.
- Use batchnorm in both generator and discriminator.
- Don’t use fully connected hidden layers.
- Use ReLU activation in the generator of all layers except the output (which uses Tanh).
- Use LeakyReLU activation in the discrimination of all layers except the output (which does not use an activation).
- Implement a DCGAN.
- Train DCGAN by using MNIST dataset.
- Visualize the results.
Q.5 Wasserstein GAN (WGAN)
Reference Paper: WGAN
- What is mode collapse?
- Problem with BCE loss
- Wasserstein loss
- Conditions of Wasserstein’s critic and 1-Lipschitz continuity enforcement
- Implement WGAN and train it on MNIST and CIFAR-10 datasets.
Q.6 Conditional GAN
Reference Paper: Conditional GAN
- What is the difference between conditional and uncondionalt GAN?
- How conditional GAN works? (You can refer to the paper)
- Implement conditional GAN on MNIST and CIFAR-10 dataset (or use cat dataset).
- What is controllable generation?
- What is the difference between conditional and controllable generation?
In the following task, you need to train a GAN with CelebaA dataset. Then use that GAN for controllable generation as follows. Here is an example of controllable generation with a pre-trained classifier.
- Implement a controllable generation method (classifier gradient).
- Train a unconditional GAN with CelebaA dataset
- Train a classifier for a certain feature (e.g., binary classifier with/without eyeglasses)
- Use that pretrained classifier to change the z vector (run gradient ascent).
- What is z-space disentanglement?
- Find out methods for z-space disentanglement.
Q.7 Cycle GAN
Reference Paper: Cycle GAN
- What is unpaired image-to-image translation?
- Overview of Cycle GAN (Two GANs)
- Explain different losses (Cycle consistency loss, least square loss, identity loss)
- Implement a Cycle GAN.
- You can try any dataset from here.
Q.8 GAN Evaluation
Explain how to evaluate GANs.
Explore the following metrics for evaluating GANs.
Explain how they works and evaluate your previously trained GAN with CIFAR-10 with the above metrics.
Chapter 7: Attention Mechanisms
Q.1 Attention Pooling
- Explain what attention mechanism is.
- Why attention mechanism is different from fully connected layer or pooling layer?
- Consider a function \(y_i = 2 sin(x_i) + x_i^{0.8} + \epsilon\). Generate a synthetic dataset for 50 examples.
- Implement average pooling.
- Implement a non-parametric attention pooling (Nadaraya-Watson kernel regression).
- Implement a parametric attention pooling.
Q.2 Attention Scoring Functions
- Explain additive attention scoring function with a toy example.
- Explain scaled dot-product scoring function with a toy example.
Q.3 Bahadanau Attention
To understand this attention mechanism, we need to consider a language translation problem (encoder-decoder architecture).
- Implement an RNN with Bahadanau attention
- Dataset : French-English
Q.4 Multi-Head Attention
- Why do we need multi-head attention instead of single attention pooling?
- Implement a multi-head attention with a toy example.
- Verify the output tensor shape.
Q.5 Self Attention and Positional Encoding
- Explain self attention with an example.
- Explain positional encoding with an example.
Q.6 Transformer
- Explain overview of the transformer model.
- Implement a transformer
- Train it with the previous French-English dataset.
Q.7 Vision Transformer
Reference Paper: ViT
- Explain overview of ViT.
- Implent a ViT.
- Train it with CIFAR-10 without using pre-trained weights.